T. Jarrett, IPAC
(980218)
GALWORKS goes to great lengths to compute all sorts of 2-D image/radial properies of "extended" sources in order to separate real galaxies from stars and their evil cousins double & triple stars. These discrimination parameters, including "mxdn", "sh", "msh", "wsh", "r23", "r1" and "vint", are discussed in Star - Galaxy Discrimination Parameters . Thresholding on these "score" parameters effectively separates out the chaff, but there are always surviving "bogies" (non-galaxies, like double stars) that go into and contaminate the extended source database. In order to achieve the level-1 reliability specification for the extended source catalog (99%), it is therefore necessary to apply more stringent tests to eliminate these buggers.
For simplicity, GALWORKS samples (thresholds) the score parameter space in only one or two dimensions at a time (e.g., "r23" vs. Kmag). For post-processing, however, we would like to perform a more optimized sampling of the N-space that the parameters form -- use all of the information simultaneously to form an optimized "score". The most obvious thing to do is combine or average all of the scores to form one score. However, this "mean" score is doomed to failure for three basic reasons,
The only way to combine the scores to form an effective "super" score is to perform a weighted average. The weights gauge the relative importance of the individual score parameters, as well as provide a uniform normalization. The weights, however, cannot help with variable source density; instead, they must be determined for densities representing high glat (most of the sky), moderate glat (say, from 10 to 30 degrees) and low glat (< 10 deg).
Method
Using RTB data fields, we can fully explore the space formed by the score weighted average and determine the optimum weights by maximizing the reliability.
For each source, (note: since we are using RTB data, we know what each source is: galaxy, double star, triple star, artifact, etc), we perform the following calculation (weighted average):
SS(i) is the "super" or combined score for the ith source. We do this for all of the sources, then apply a threshold to SS, and compute the resultant C & R. Our goal is to find the best set of W(j) that maximizes R (with C >= Clim, say 95%).
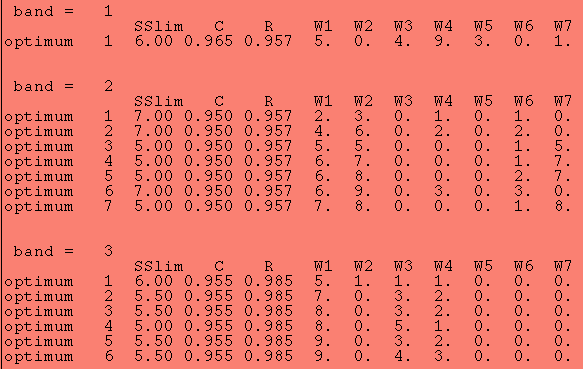
Let's suppose that we may assign a weight for each score between 0 and 9 (with integer spacing). And let's suppose that we have a total of 7 scores, including "mxdn", "sh", "msh", "wsh", "r23", "r1", and "vint". Our score space is then 7 dimensions (ignoring integrated flux). Then the total number of possible combinations is 10**7, or 10 million. We thus explore 10 million different combinations of the 7 score parameters to arrive at the best combination of weights. We can use these optimized weights to compute a "super" score for each object and threshold on this score to separate bogies from real extended sources (galaxies). Since the relative importance of the scores changes with both integrated flux and with source density, we want to perform this operation for different mag bins and for different source densities (as noted above). This study considers three different mag bins: bright (everything brighter than the last level-1 spec bin), the last level-1 spec bin (e.g., 13.0 < K < 13.5), and a faint band beyond the lev-1 spec (e.g., 13.5 < K < 13.8). And of course we do the operation for each band, JHK, separately.
As a preliminary stab at this complicated (and cpu intensive) procedure, I have chosen the following RTB set:
Last Level-1 Spec Mag bin
Mag bin: 14.5 <= J < 15.0, 13.8 <= H < 14.3, 13.0 <= K < 13.5
We require an "internal" completeness of at least 95%. We then optimize the reliability with a running threshold on the SS ("super" score). We will report the weights that give the best R and we will report the SSlim (threshold on SS that gives the best R). Note that it is possible (in fact, likely) that more than one set will be reported (i.e., we have degeneracy in the "best" weight combination).
The results are given below. Notice that there is more than one solution for H and K bands (band = 2 & 3, respectively). Also notice that several weights are zero -- thus the corresponding score is nullified in some cases. The optimum reliability is 96%, 96% and 99%, JHK, respectively.
SSlim == SS threshold at with the optimum R occurs
W1 == applies to "mxdn"
W2 == applies to "sh"
W3 == applies to "msh"
W4 == applies to "wsh"
W5 == applies to "r23"
W6 == applies to "vint"
W7 == applies to "r1"
Important Caveat:
Although the weights given above are the "optimal" set, there are
many MANY other combinations that are nearly as good. That is why some
of the weights are zero -- it is not that they are completely unimportant,
but rather it simply means that a value of zero is tolerable.
To demonstrate this, I ran the algorithem using only 7 possible weights
per score (as opposed to 10, or about 800 thousand total possible combinations)
and I came up with an entirely different set of weights.
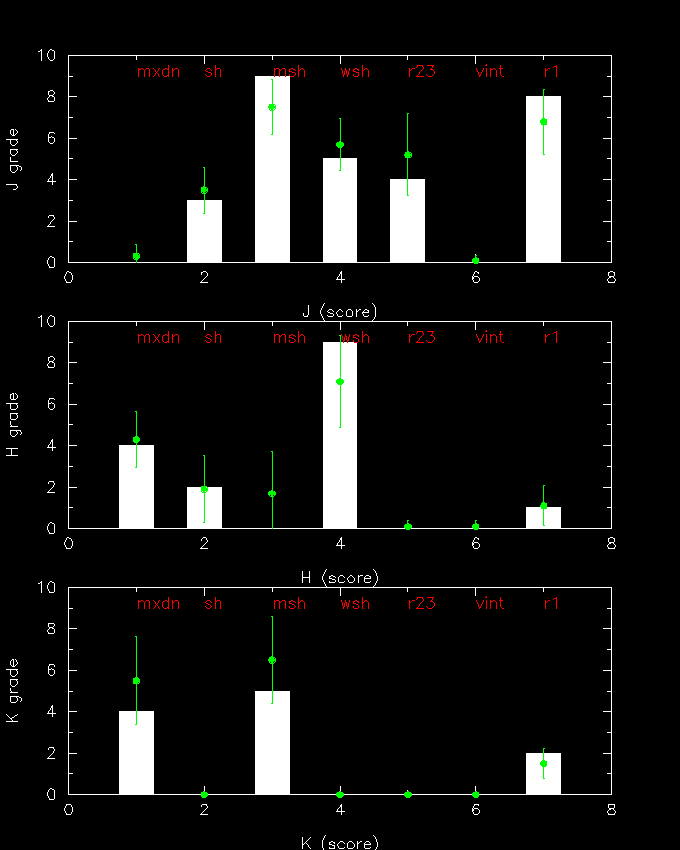
In any event, we have to settle on one set of weights, so it is not too critical which set are used as long as they are close to optimal. One way to choose the best set from a degenerate set is to compute the "mean" weight per score (in the degenerate set) and pick the weight set that most closely matches the mean. The following plot demonstrates this method:
Here the green points represent the mean weight for the degenerate set, and the error bars are the sigma-pop for the set. The white bars are then the "solution" set of weights that most closely fit the means (green points). Caution: the mean values (green points) do not themselves give the best solution (why? because they are decoupled from each other); instead they provide a "clue" as to the most "popular" solution (white bars). Each solution of the degenerate set is equally valid, but we want to pick from the set the most common ("popular") to represent our final solution.Ok, what can we conclude from the bar graph? At least for the mag bin sample here (last faint bin relevant to lev-1 spec) and low source density (high glat) , the most "important" scores are "mxdn", "msh", "wsh" and "r23" for J, "mxdn", "sh" and "r1" for H and "mxdn", "msh" and "wsh" for K. Again, this is not to say that the other scores are not important (see caveat above). Also, we should be more careful by what we mean "important". The weights not only tell us what is "important" but also fold in the normalization (thus, for example, we need to crank up the weight for "r23" in order to compete with "sh", because "r23" is always smaller than most of the other scores).
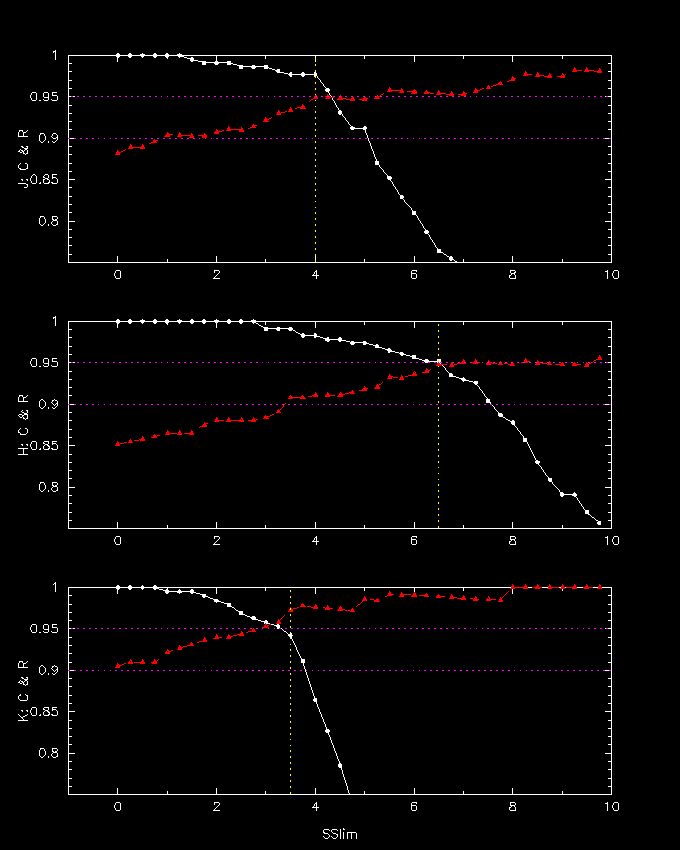
We can view the change in C & R as a function of the SS limit with the use of our optimized score weights (see bar graph above). Note that we required C to be at leat 95% for optimization.
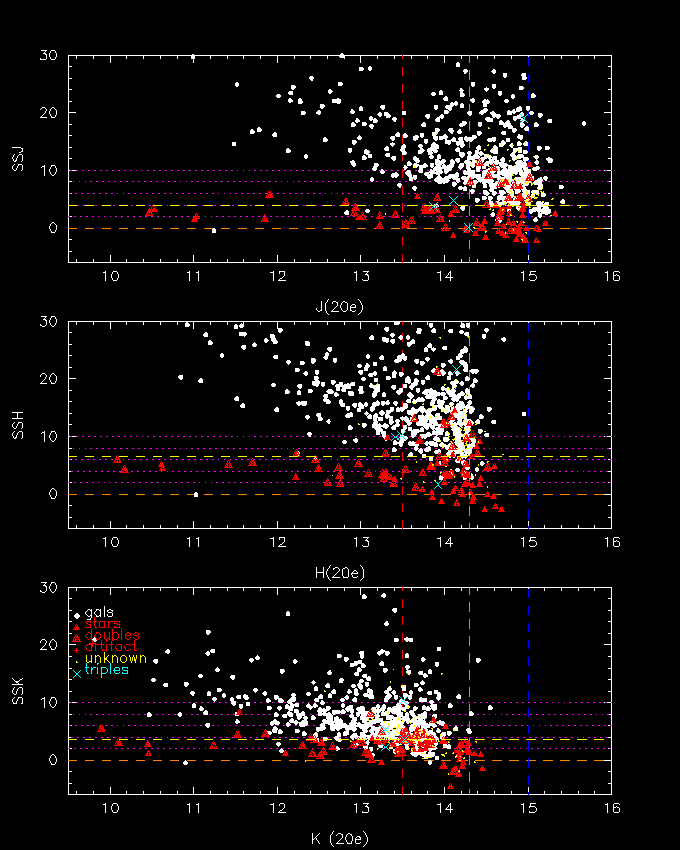
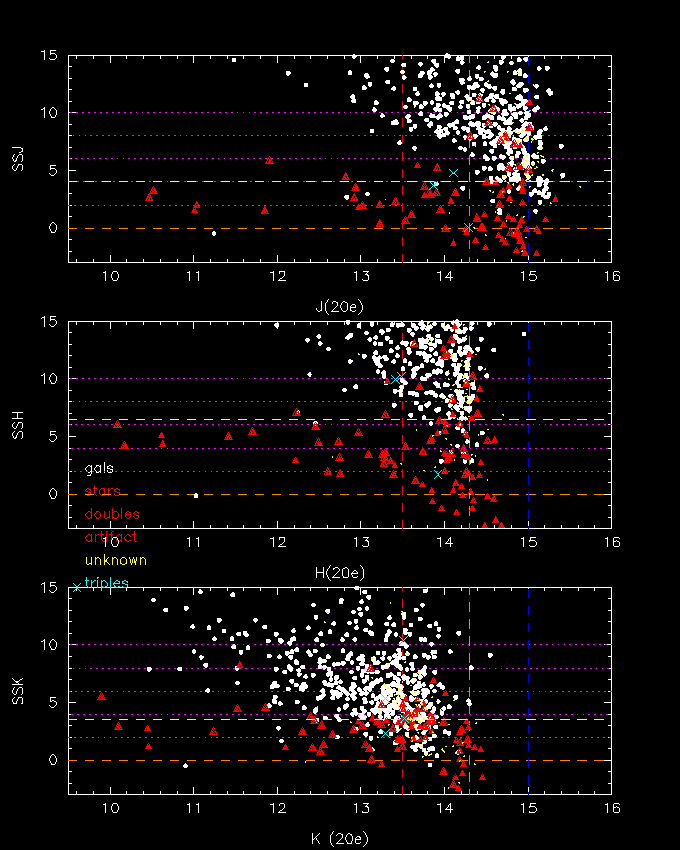
What about the other mag bins? In order to see how the optimized weights affect the other bins, below we plot the SS score for all sources, galaxies and bogies alike. Note: the weights used to compute SS for all of the objects were derived using only objects with mags between 14.5 < J < 15, 13.8 < H < 14.3, 13.0 < K < 13.5. In principle, we want to derive weights for each mag bin, then use the approp weights to compute SS. At this time, however, we need only use one set to demonstrate the method.
The SS score does an excellent job at separating false galaxies from real galaxies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}